hbase进阶与大数据存储调优案例。解决高并发大批量写入hbase丢数据问题,优化查询效率从5min减少到7s。
hbase介绍
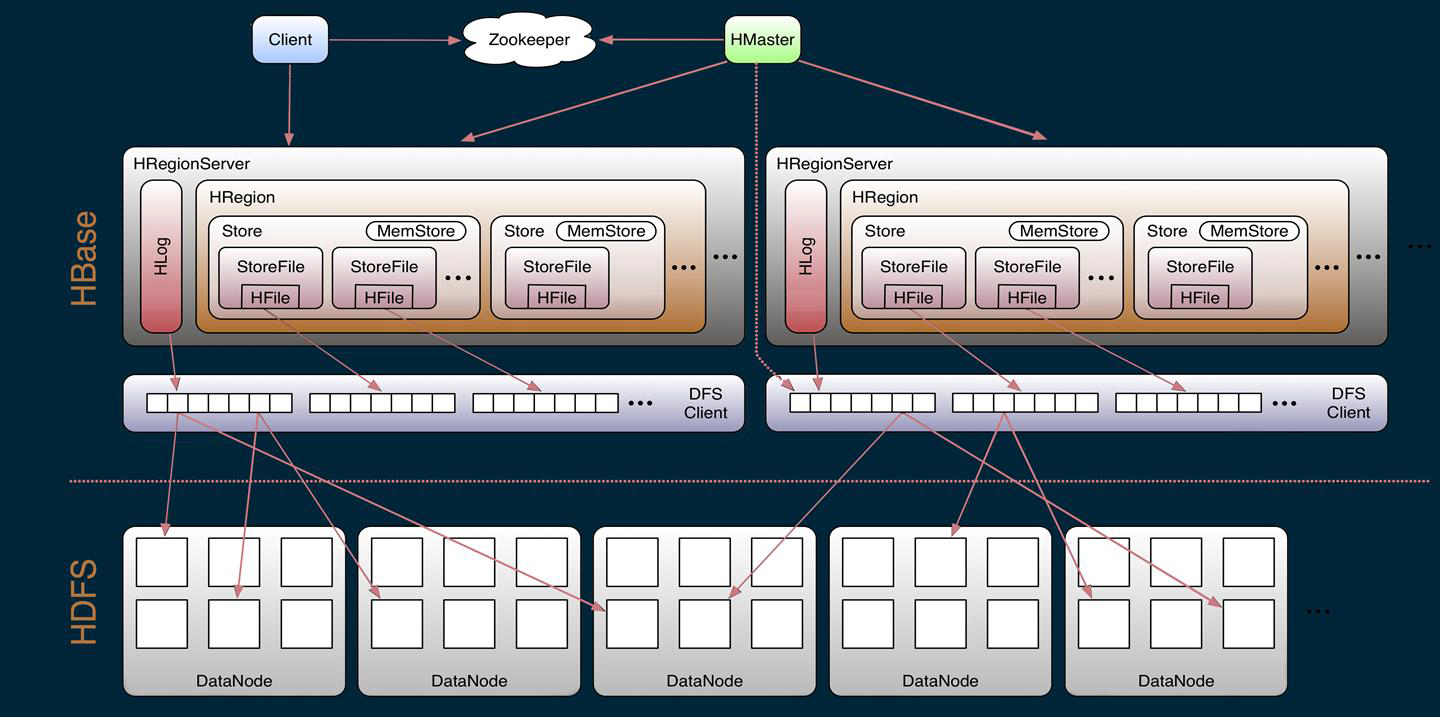
hbase底层原理
每个ColumnFamily建一个HStore,HStore由一个Memstore和一系列HFile组成。Memstore位于Region Server的主内存,HFile则被写入到HDFS。需要被写入的数据首先写入Memstore,达到一定阈值flush到HFile中,每次flush都会创建一个新的HFile。
StoreFile底层以HFile格式KeyValue(hadoop二进制文件)保存,一个StoreFile对应一个HFile。
当region的某个列族达到一个阈值(默认256M)时就会split出新的region。
memstore文件比hfile文件大,原因在于heapSize()内存中一个KeyValue对象除了本身实际内容外,还有 64byte是对象的内部实例等占用了部分空间。参考:HBase MemStore与HStoreFile的大小分析
关于LSM
LSM树原理:把一棵大树拆分成N棵小树,它首先写入内存中,随着小树越来越大,内存中的小树会flush到磁盘中,磁盘中的树定期可以做merge操作,合并成一棵大树,以优化读性能。No-SQL数据库一般采用LSM树作为数据结构,HBase也不例外。
LSM数据更新只在内存中操作,没有磁盘访问,因此比B+树要快。对于数据读来说,如果读取的是最近访问过的数据,LSM树能减少磁盘访问,提高性能。 LSM树实质上就是在读写之间得取平衡,和B+树比相,它牲牺了部份读性能,用来大幅进步写性能。
全量日志表
该表存储接口请求的所有业务上报数据,每天几亿。
region server
数量:29
单个 server 的 max heap 50G,Direct Memory Configured 50G,Memstore Size 14.6G
region
共80个,每个region40G存储空间
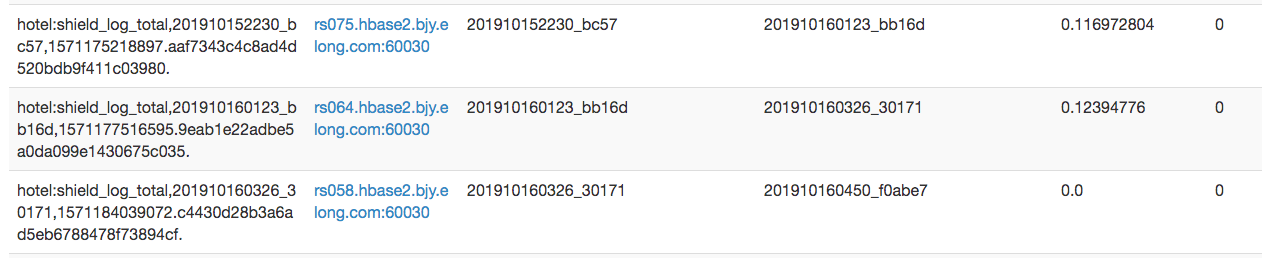
但是只有一个region有效,其他region的数据在spilit完以后已经过期删除,该region信息如下:
| Region Name | Num. Stores | Num. Storefiles | Storefile Size Uncompressed | Storefile Size | Index Size | Bloom Size | Data Locality |
|---|---|---|---|---|---|---|---|
| hotel:shield_log_total,202004131244_e74d,1586919481374.2bc43dc5c0a8a33675177eb79b48a861. | 1 | 39 | 6188861m | 1728442m | 4368608k | 4219944k | 1.0 |
参考:单个region server 的 region 数目上限、hbase split操作
表结构
1 | 'hotel:shield_log_total', {NAME => 'log_info', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => '2592000 SECONDS (30 DAYS)', COMPRESSION => 'LZO', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0', CONFIGURATION => {'hbase.hregion.max.filesize' => '42949672960'}} |
配置
mob说明:https://blog.csdn.net/bingdianone/article/details/84863248
1 | # region 副本数 |
写入问题
热点问题
rowkey写入规则为yyyyMMddHHmm_唯一标识,存在写入热点问题,频繁超时、日志丢失,需要优化。
flush频率较高
如图所示,flush间隔时间大约10s,每次flush128M数据

compact问题
现在的配置是每个region最多40个hfile,flush频繁导致compact也会很频繁。
参考
compaction触发条件:memstore flush时检查、定时任务周期检查、hbase shell 或 master ui 或 hbase api 等方式手动触发。
写请求非常多导致不断生成HFile,但compact的速度远远跟不上HFile生成的速度,这样就会使HFile的数量会越来越多,导致读性能急剧下降。为了避免这种情况,在HFile的数量过多的时候会限制写请求的速度:在每次执行MemStore flush的操作前,如果HStore的HFile数超过hbase.hstore.blockingStoreFiles (默认7),则会阻塞flush操作hbase.hstore.blockingWaitTime时间,在这段时间内,如果compact操作使得HStore文件数下降到回这个值,则停止阻塞。另外阻塞超过时间后,也会恢复执行flush操作。这样做就可以有效地控制大量写请求的速度,但同时这也是影响写请求速度的主要原因之一。
HBase主要有两种minor策略:RatioBasedCompactionPolicy(0.94默认,我们采用的)和ExploringCompactionPolicy(0.96后默认,IO性能提升10%)
region split 问题
参考:HBase最佳实践之Region数量&大小、HBase Region自动切分的所有细节
memstore总大小默认为堆内存的40%
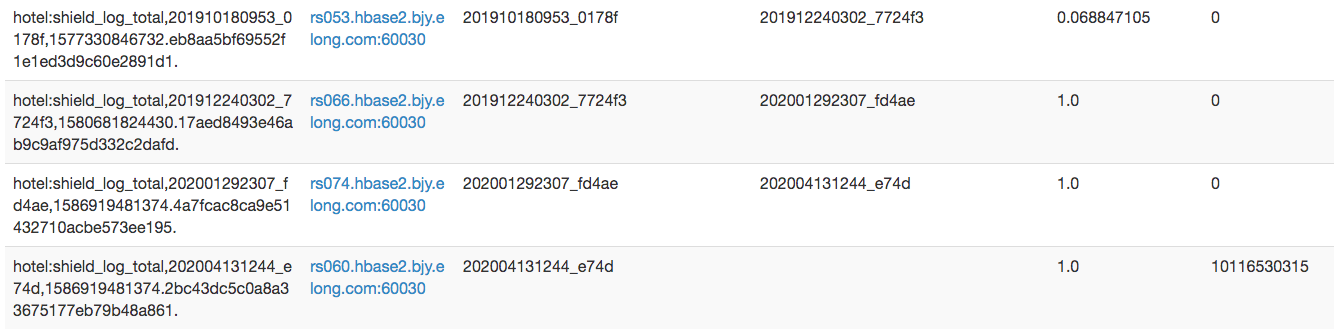
当单个hfile大小超过限额时,会出现 region split。目前全量日志表没有做预分区,因此所有日志都向一个region写,当写入频繁而region非常大时,会出现Hbase写入量大导致region过大无法split
正常split:隔几天split一次

太大无法spilit:很久没有split
写入问题分析和解决思路
由于hbase数据是按照字典序排序,没有分区会导致连续数据集中写入同一个region,所以解决写入热点问题主要原理是将并发写入的数据打散,分布均匀的写入到多个region。
写入数据总览
region名:hotel:shield_log_total,202010281022_abdf:,1604395921838.f6a7dfcbe71eb36e12047c2c1e1dae40.
文件起始 202010281022,截止到202011041022,Storefile Size Uncompressed 4788807m(4676G),Storefile Size 1352194m(1320G)
共计7天的数据,按照压缩后的文件大小计算后约 188.6G/d,约 7.86G/h,按照总量是35G/h。
解决方案先预分区,然后根据读取性能需要,将messageId按照hash方式映射到各个region中,再加上时间戳。分区案例:
create 'hotel:shield_log_analyse_ip', {NAME => 'info', TTL => '7776000'}, {SPLITS => ['20', '40', '60', '80']}计算每RS(假设一个表)region的数量的公式为:
((RS memory) * (total memstore fraction)) / ((memstore size)*(# column families))
例如: 如果 一个RegionServer配置的内存是16g,使用默认配置( hbase默认regionserver分给memstore的比例是0.4 , 默认的menstore的占用128M内存 ), 一个CF,那么这个regionServer下的region的个数大约为 16384 * 0.4 / (128*1) = 51个,实际测试大于这个数 一两倍 也没太大的问题。 一个HBase表包含一至多个region,那么表的数目上限也是可以估算出来的。
读取问题
全量扫描读取缓慢
读取问题分析和解决思路
查询条件均包含时间,核心的几个处理流程基本上都会指定渠道或actions,日志分析还包括resultType因此在设计rowkey可以给rowkey增加这些字段,让查询速度更快。
避免热点的话就需要预分区,比如可以分为100个预分区(00-99),按照上面统计的35G/h,这样每个分区每小时0.35G数据。提高写性能主要是减少compact次数,按照每个memstore 128M,大约350M/128M=3次/h,约20分钟写一次hfile,而超过40次才会发生compact,这样compact的间隔可以控制在40/3=13h。每天大约发生两次compact,hbase写入由原先的10s一次,大约12h发生4000次compact,写入性能大大提高。
预分区前缀会导致查询时遍历所有region,导致查询性能降低这个是不可避免的一个趋势,可以通过多线程去解决这个问题。但是由于需要兼容之前的逻辑,所以需要在每个region里查询时都要尽量带上时间戳。但是rowkey也不能设计的过长避免浪费内存(写入和compact都以kv形式存在),所以初步设计rowkey如下:
分区号_yyyyMMddHHmm_source_method_resultType_uuid,例如 25_202011042324_Andriod_getHotelList_1_ask54n83fal4
最后就是考虑查询时的代码兼容。老表数据量严重超标而且无法split已经不堪重负,直接写入新rowkey没多大意义。而且预分区需要在建表时指定,新建一个表数据双写,等过了几天之后一键切换表名。然后就是查询,考虑兼容时间问题,在每个region查询时都要在分区数字之后加上时间戳。website项目里主要是去修改公共的查询方法,在时间戳前面加上region分区号,遍历每个region指定时间的数据后统一返回。mapreduce需要在main入口输入起始startRowkey和endRowkey,加入正则或者字符串过滤器。
bloomfilter提高随机读性能,row只针对行,rowcol针对行和列,可以只查满足条件的storefile。但该表主要是scan,没有get场景,不需要设置bloomfilter。
第一版建表语句如下:(随机分区)
1
create 'hotel:shield_log', {NAME => 'log_info', TTL => '2592000', VERSION => '1'}, {SPLITS => ['00', '01', '02', '03', ..., '99']}
保留30天数据,预分区100个,每份数据保留版本1个
效果:但无法兼容之前的分页查询
第二版建表语句如下:(新版,翻转时间串)
1
create 'hotel:shield_log', {NAME => 'log_info', TTL => '2592000', VERSION => '1'}, {SPLITS => ['00', '01', '02', '03', ..., '59']}
保留30天数据,预分区60个(一分钟一个分区),每份数据保留版本1个
rowkey设计:
二期:mmHHddMM_periodId_sourceId_uri_resultType_uuid
例如42082511_2_112_123_/abc/dss_ask54n83fal4
一期:mmHHddMM_periodId_sourceId_method_resultType_uuid
例如 42082511_1_100_102_getHotelDetail_kasdlew23fd
效果:原来需要查一分钟的日志量需要耗时60s左右,现在只需要3s。但是需要对原来的时间格式做修改,仍然无法做到不改动其他逻辑兼容之前顺序设计的时间格式
最终修改版建表语句:(分钟数单独作为分区位,时间串保持之前的顺序格式)
mm_yyyyMMddHHmm_periodId_sourceId_uri_resultType_uuid
例如 12_202012031012_2_233_/abc/ddd_asdlkfasd3
效果:完全兼容老版本,并减少scan扫描的数据量。经测试,原表查询5分钟的数据,新表只需7s。
hbase其他优化
http://www.blogjava.net/DLevin/archive/2015/08/22/426877.html
http://www.blogjava.net/DLevin/archive/2015/08/22/426950.html
https://zhuanlan.zhihu.com/p/69740865
压缩
HBase在写入数据块到HDFS之前会首先对数据进行压缩,再落盘,从而减少磁盘空间使用量。而在读数据的时候首先从HDFS中加载出block块之后进行解压缩,然后再缓存到BlockCache,最后返回给用户。
| 压缩算法 | 压缩比率 | 压缩速度 | 解压速度 |
|---|---|---|---|
| GZIP | 13.4% | 21 MB/s | 118 MB/s |
| LZO | 20.5% | 135 MB/s | 410 MB/s |
| Snappy | 22.2% | 172 MB/s | 409 MB/s |
综合来看,Snappy的压缩率最低,但是编解码速率最高,对CPU的消耗也最小,目前一般建议使用Snappy。
后续跟踪
按照新方案设计的全量日志表shield_log在读写方面完全解决掉了之前的痛点问题,但是时间长了以后会发现,仅过去一个月切分出了800个分区。。原因还是日志量过大split分区频繁。此时需要加以其他辅助,例如将老的region进行合并或删除等。